Unsupervised Machine Learning: Finding Hidden Patterns in Data
In the world of Artificial Intelligence, data is everywhere. But not all data comes with labels explaining what it represents. This is where **Unsupervised Mach...
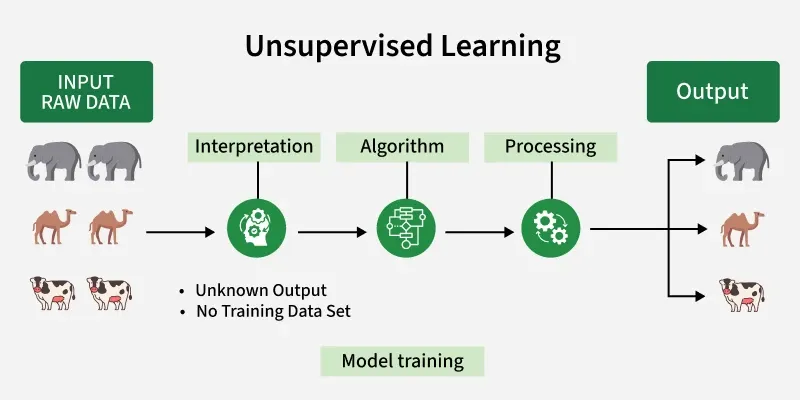
In the world of Artificial Intelligence, data is everywhere. But not all data comes with labels explaining what it represents. This is where Unsupervised Machine Learning becomes powerful. Instead of learning from labeled examples, unsupervised learning explores raw data and discovers hidden structures, patterns, and relationships on its own.
It is like giving a computer a large pile of puzzle pieces without the picture on the box and letting it figure out how the pieces fit together.
What is Unsupervised Machine Learning?
Unsupervised Machine Learning is a branch of Machine Learning where algorithms analyze and group unlabeled data without predefined outputs.
Unlike supervised learning, where the model learns from labeled examples, unsupervised learning tries to answer questions like:
-
Are there natural groups in this data?
-
What patterns exist?
-
Can similar data points be clustered together?
The system learns the structure of the data rather than predicting a specific answer.
Why Unsupervised Learning Matters
In real-world scenarios, labeled data is often expensive and time-consuming to obtain. However, large volumes of unlabeled data are readily available.
Unsupervised learning helps organizations:
-
Discover hidden insights
-
Detect unusual patterns or anomalies
-
Understand customer behavior
-
Reduce complex data into simpler representations
This makes it extremely valuable in modern Artificial Intelligence applications.
Key Types of Unsupervised Learning
1. Clustering
Clustering algorithms group similar data points together based on their features.
Example:
An online store may group customers based on purchasing behavior to identify different types of buyers.
Common clustering algorithms include:
-
K-Means Clustering
-
Hierarchical Clustering
-
DBSCAN
Clustering is widely used in marketing, recommendation systems, and social network analysis.
2. Dimensionality Reduction
Modern datasets often contain many features, making them complex and computationally expensive.
Dimensionality reduction techniques simplify datasets while preserving important information.
A popular method is Principal Component Analysis, often called PCA.
Benefits include:
-
Faster computation
-
Easier visualization
-
Reduced noise in data
Real-World Applications
Unsupervised learning powers many technologies we interact with daily.
Customer Segmentation
Businesses group customers with similar behavior to improve marketing strategies.
Recommendation Systems
Streaming platforms analyze viewing patterns to suggest relevant content.
Fraud Detection
Financial systems identify unusual transaction patterns that may indicate fraud.
Image and Pattern Recognition
Algorithms detect structures and similarities within visual data.
These applications are a core part of modern Data Science workflows.
Example Workflow
A typical unsupervised learning pipeline may look like this:
-
Collect raw data
-
Clean and preprocess the data
-
Select an unsupervised algorithm
-
Train the model on unlabeled data
-
Analyze patterns and insights
The results are often interpreted by data scientists to extract meaningful conclusions.
Advantages of Unsupervised Learning
-
Works with unlabeled data
-
Can reveal hidden patterns
-
Useful for exploratory data analysis
-
Helps simplify complex datasets
Limitations
Despite its strengths, unsupervised learning has some challenges:
-
Results can be difficult to interpret
-
No clear “correct answer”
-
Sensitive to data quality and preprocessing
Because of this, domain knowledge is often required to understand the patterns discovered.
Final Thoughts
Unsupervised Machine Learning is like giving machines the ability to explore data independently. Instead of being told exactly what to look for, algorithms search for patterns that humans might miss.
As data continues to grow rapidly, unsupervised learning will play an increasingly important role in uncovering insights and driving intelligent systems.
In many ways, it represents the next step toward machines that can learn from the world without explicit instructions.