The architecture behind ChatGPT, Google Translate, and modern AI explained through plain intuition.
Before Transformers, language models had to read sentences word by word, like reading a book with one eye covered, processing one letter at a time. Transformers...
Before Transformers, language models had to read sentences word by word, like reading a book with one eye covered, processing one letter at a time. Transformers changed everything. They read the entire sentence at once and let every word talk to every other word simultaneously.
Here's an intuitive walkthrough of exactly what happens inside a Transformer, using the phrase "cat eats fish" as our example.
Step 1 : Words become numbers
Computers can't understand the word "cat." So the first job is to convert each word into a list of numbers called an embedding. Think of it as assigning every word a coordinate in a vast map of meaning, where words with similar meanings sit closer together.
At this stage, "cat," "eats," and "fish" are each just a pair of numbers floating in space with no sense of their order in the sentence.
Step 2 : Telling words where they stand
Since the Transformer reads all words at the same time, it has no natural way to know that "cat" comes first. To fix this, a positional encoding is added — a subtle fingerprint stamped onto each word's numbers based on its position in the sentence.
Think of it like seat numbers at a concert: the music is the same, but your seat tells you where you are relative to everyone else.
After this step, the model knows both what each word means and where it appears.
Step 3 : The attention mechanism (the magic part)
This is the heart of the Transformer. For every word, the model asks three questions:
Query : "What am I looking for?"
When "cat" is processed, it broadcasts a query: what context do I need to understand myself?
Key : "What do I offer others?"
Each word also has a key a signal that says here's what I can tell you about myself.
Value : "What do I actually share?"
When another word finds your key useful, you hand over your value the actual information you contribute.
For our sentence, the model calculated that "cat" attends to itself 70.7% of the time, to "eats" about 19%, and to "fish" about 10%. The word naturally found its own identity most relevant which makes intuitive sense.
Why this matters
Attention lets the model understand that in "the bank by the river," the word "bank" means shoreline because "river" is nearby and earns high attention weight. The same word in "the bank approved my loan" attends to "loan" instead, and shifts its meaning accordingly.
Step 4 : Stabilising with Layer Norm
After attention, the numbers can get very large or very small making learning unstable. A residual connection adds the original word back in (so the model doesn't forget what it started with), and then layer normalisation rescales everything to a standard range. It's like adjusting the brightness and contrast on a photo so the details remain visible.
Step 5 : The feed-forward network
Once every word has absorbed context from its neighbours through attention, each word is sent through a small independent neural network the feed-forward layer. This is where more complex, non-linear patterns are learned. It's the part of the model that does the heavy reasoning, transforming blended context into richer representations.
Another round of stabilisation follows, and the encoder is done.
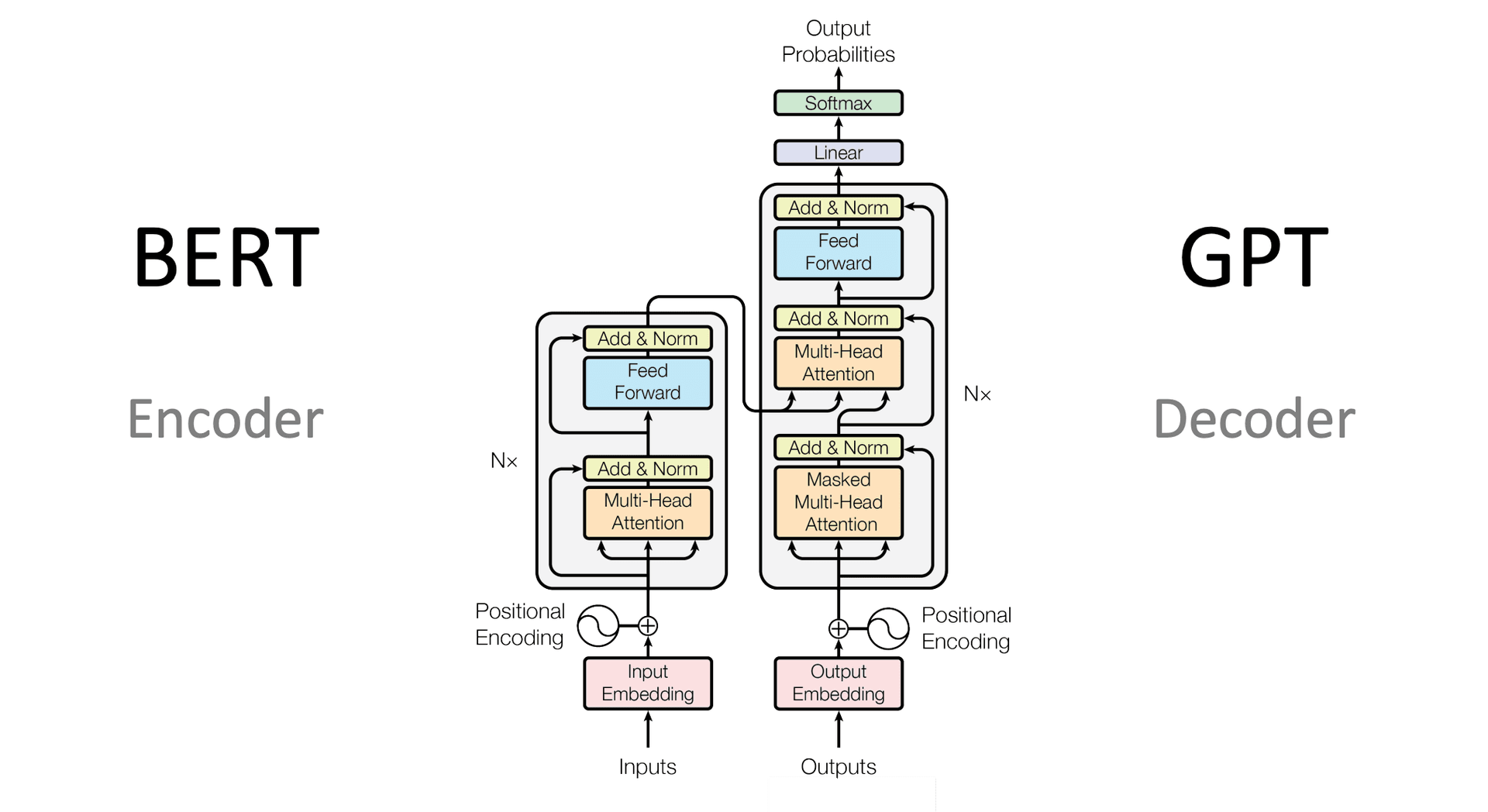
The decoder : generating output
In tasks like translation or text generation, a second half called the decoder produces the output word by word. It does something clever: it uses a mask to block future words from view while generating the current one preventing the model from "cheating" by looking ahead.
It also runs a special attention step where it looks back at everything the encoder understood about the input. This lets the decoder ask: given what I know about "cat eats fish," what's the most likely next word in the translation?
The final step is a projection over the entire vocabulary often tens of thousands of words and a softmax converts those scores into probabilities. The highest probability word is chosen as the output.
The big picture
Stack dozens of these encoder and decoder layers on top of each other, train on billions of sentences, and you get a model that can translate languages, write code, answer questions, and summarise documents all from the same elegant mechanism.